
ForFour
[kaggle]심슨 캐릭터 인식하기(The Simpsons character recongnition) 본문

The Simpsons Characters Data | Kaggle
The Simpsons Characters Data
Image dataset of 20 characters from The Simpsons
www.kaggle.com
다음 캐글 데이터 셋에서 cnn을 이용해 캐릭터 인식을 해보겠습니다.
- 먼저 필요한 라이브러리를 임포트 해줍니다.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
import seaborn as sns
import matplotlib.pyplot as plt
import requests
import cv2
import random
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay,classification_report
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline2. 주어진 자료 확인하기
- 전체 캐릭터의 수는 42명입니다.

- training dir에서 각 캐릭터마다 훈련 이미지가 주어집니다.

전체 캐릭터는 42명이지만 데이터 셋의 분포를 보면 약간의 불균형과 단편성 캐릭터의 데이터도 섞여있는 것 같습니다. 가장 데이터가 많은 호머 심슨의 데이터의 약 10%인 200개를 기준으로 200개 미만의 훈련 데이터를 가지고 있는 데이터는 버리도록 하겠습니다.

그러면 200개 이상의 데이터를 가진 20명의 주요 캐릭터가 나왔습니다.

3. 훈련 데이터 분리하기
모델을 학습시키기 위해서는 훈련 데이터를 메모리에 올려 훈련을 수행해야 합니다. CNN 모델, 총 20명의 캐릭터, 이미지 데이터 약 20000개는 kaggle notebook에서 한 번에 학습이 불가능합니다. kaggle에 대한 제약을 생각하지 않고 학습 데이터를 전부 로드하면 메모리 부족으로 세션이 초기화되니 ImageDataGenerator를 이용해 working directory에서 배치 사이즈만큼씩 학습을 진행하겠습니다.
ImageDataGenerator는 flow와 같은 기능 외에 Image Augmentation을 가능하게 합니다. 간단하게 horizontal_flip(좌우반전)의 옵션만 주어 데이터를 생성하도록 하겠습니다.
먼저 주요 캐릭터의 데이터를 working dir로 복사합니다.
def copy_image_data_2_WorkingDIR():
if not os.path.exists('/kaggle/working' + '/train_data_flow_dir'):
os.mkdir('/kaggle/working' + '/train_data_flow_dir')
# copy only characters having image data over 200
for i in char_data_over_200.keys():
des = '/kaggle/working' + '/train_data_flow_dir' + '/'+i
src = inputdir + '/'+i
print(src,des)
# if not os.path.exists(des):
# os.mkdir(des)
#print('/kaggle/working' + '/train_data_flow_dir/' +i)
try:
shutil.copytree(src,des)
except Exception as e:
pass
데이터가 복사되었다면 flow_from_directory를 통해 working dir로부터 배치 사이즈만큼 데이터가 생성되도록 하는 DataIterator를 만들고 training, valid set을 분리합니다.
4. 모델 정의하기
CNN 모델 구조를 보면 대부분 비슷한 구조를 가지고 있습니다. 1-2개의 conv layer 이후 pooling과 dropout, 마지막 dense layer로 구성된 구조가 대부분입니다. 같은 구조로 8개의 layer를 쌓아 모델을 구성해보겠습니다.

5. 학습하기
kaggle에서 제공해주는 GPU모델을 사용해 학습을 진행합니다. imageGenerator를 이용해 학습을 진행하고 callback으로 val_acc이 가장 높은 모델을 save 하도록 하겠습니다. epoch를 100을 주어 진행했는데 epoch 20-30 이후부터는 accuracy 85를 넘어 뚜렷한 학습을 보이지 못했습니다. 중간에 학습이 끊어져 100 epoch를 전부 진행하지는 않았지만 이미 정확도 상승폭이 현저하게 떨어져 있던 상태였기 때문에 마지막으로 저장된 18번째 epoch모델을 사용하여 test set recognition을 진행합니다.
checkpoint_path = '/kaggle/working/weights-improvement-{epoch:02d}-{val_accuracy:.2f}.hdf5'
checkpoint = tf.keras.callbacks.ModelCheckpoint(checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max')
result = model.fit_generator(train_flow_gen,
steps_per_epoch=train_flow_gen.samples / 32, #32 = batch_size
epochs=100,
validation_data=valid_flow_gen,
validation_freq=1,
callbacks =[checkpoint])
6. 모델 성능 평가하기
중간에 저장된 모델은 val_acc 86%의 정확도를 가지고 있었습니다.
testdata set 폴더에 저장된 데이터를 이용해 평가를 진행한 결과 정확도 93%로 일단 심슨을 보지 않은 저보다는 훨씬 더 똑똑한 캐릭터 인식 모델이 된 것을 볼 수 있었습니다. confusion matrix도 확인을 해보겠습니다.
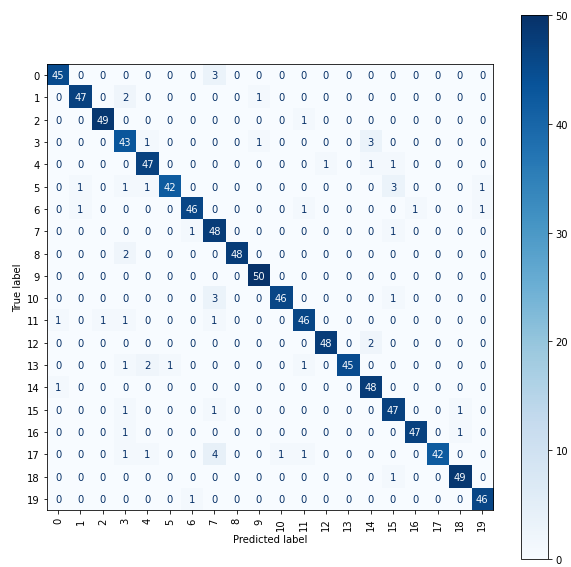
정확도와 confusion matrix 모두 꽤 준수한 성능을 보여주는 모델이 완성되었습니다.
'kaggle & ML' 카테고리의 다른 글
| PCA with eigenvector, eigenvalue (0) | 2021.12.11 |
|---|---|
| [kaggle]심슨 캐릭터 인식하기 - additional(삽질과 모델 개선) (0) | 2021.11.28 |

