
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- vscode
- 시작
- 파일권한
- venv
- 카카오 오픈빌더
- 운영체제
- braces
- flask
- Mac
- 챗봇
- gcp
- Python
- 도커
- nohub
- 노션
- 클라우드
- Windows
- 구글클라우드
- OS
- 카카오톡 챗봇
- jinja2
- graphQL
- Lambda
- chatbot
- 플라스크
- cloud
- GQL
- docker
- AWS
- ssh
Archives
- Today
- Total
ForFour
[데이터베이스]인덱스(index)란? 본문
이 글은 다음의 두 책을 메인으로 참고하여 정리한 글입니다.
Fundamentals of Database Systems (7th Edition)
인덱스(index)란?
책의 목차와 비교하기도 하지만 목차보다는 책의 색인에 가깝다*. 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 인덱스를 활용하면 select 외에도 update나 delete의 성능도 향상된다. 수정, 삭제 연산을 수행하기 위해서는 대상을 조회해야 작업할 수 있기 때문이다.
Type of Indexes
Single-level indexes
- 정렬된 파일 기반 인덱스
- 파일이 정렬되어 있기 때문에 이진 탐색이 가능하다.
- 기본 인덱스(primary index), 보조 인덱스(secondary index), 클러스터링 인덱스(clustering index). index를 기본키에 걸면 기본 인덱스, 다른 컬럼에 걸면 보조 인덱스라고 한다.
- dense, sparse(nondense) index로 구분될 수 있다. dense(밀집) index는 인덱스와 데이터의 모든 매칭(entery)이 발생하고 sparse(nondense) index는 뜨문뜨문(구간별) 매칭이 발생한다.

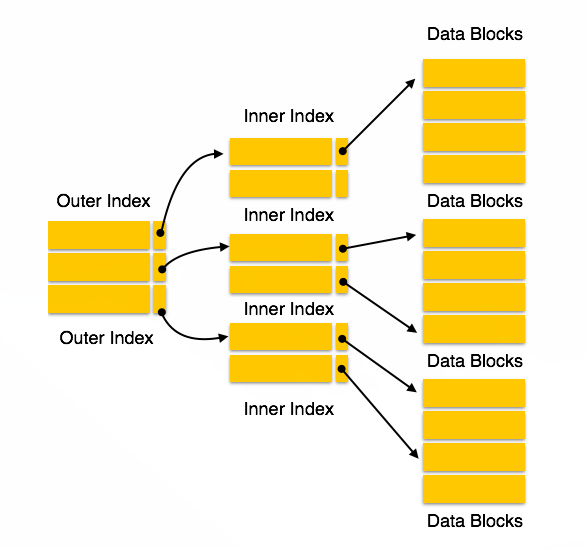
Multilevel indexes
- 트리 데이터 구조 사용 인덱스
- 인덱스를 위한 인덱스
Index Data Structure
B-Tree
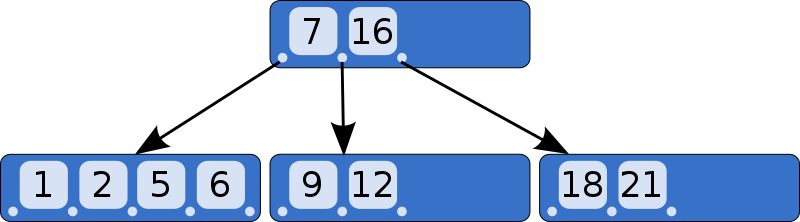
이진트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다. - [위키백과]
- Balanced-Tree로 트리의 균형이 맞다.
- 모든 노드가 실제 레코드를 가리킨다.
B+Tree

- B-Tree의 변형버전이다.
- B+Tree는 리프노드에만 데이터 포인터가 존재한다.
- 같은 level의 노드들끼리 연결되어 있다.
- 순차 정렬이 되어있어 범위 탐색에 유리하다. 검색의 시간 복잡도는 O(logN)이 걸린다.
B-Tree vs B+Tree
- B-Tree는 모든 노드에 데이터 포인터가 존재하지만 B+Tree는 리프 노드에만 존재한다.
- B-Tree는 순차 접근이 어렵지만 B+Tree는 용이하다.
- B-Tree는 키의 중복이 없지만 B+Tree는 존재한다.
- B+Tree는 리프노드끼리 연결되어있다.(linked list) 순차 접근이 가능하다.
Hash Index
해시 인덱스는 해시테이블을 이용한 인덱스로 해시값을 사용한다. 때문에 범위 검색에는 사용할 수가 없고 등가 비교에 의한 검색으로밖에 사용하지 못하지만 그 속도가 매우 빠르다는 특성이 있다.
그 외 Index
R트리 인덱스, 함수 인덱스, 비트맵 인덱스, Fractal-Tree, 클러스터 인덱스
인덱스 장단점
- 장점 : 테이블을 조회하는 속도와 그에 따른 성능 향상 시킬 수 있다.
시스템의 부하를 줄일 수 있다. - 단점 : 인덱스를 관리하기 위해 db 10%정도의 저장 공간이 필요하다.
인덱스 관리의 추가작업이 필요하다. 잘못 사용할 경우 오히려 성능이 저하된다.
CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸면 오버헤드가 커지고 인덱스의 크기가 비대해져 성능이 저하될 수 있다.
인덱스를 사용하면 좋을 경우
- 규모가 작지 않는 테이블
- 연산이 자주 발생하지 않는 컬럼
- join이나 where , order by에 자주 사용되는 컬럼
- 중복도가 낮은 컬럼 등..
'개념 챙기기' 카테고리의 다른 글
| [운영체제]Linux rm command 근데 이제 rf를 곁들인.. (0) | 2021.05.12 |
|---|---|
| Visual Studio Code에서 C/C++ 개발환경 세팅하기 (0) | 2021.02.20 |
| 쉘 스크립트(shell script) 기본 문법 (0) | 2021.01.28 |
| [운영체제] Kernel과 Shell (0) | 2021.01.26 |
| AWS 서비스 종류 (0) | 2021.01.08 |
'개념 챙기기' Related Articles
more




Comments